


Amélioration de la pertinence d'Elasticsearch chez Decitre
Introduction
Nous verrons ici la démarche utilisée lors de l’amélioration de la pertinence de recherche d’un des outils de Decitre, suite à sa migration vers Elasticsearch.
### Contexte
![]()
Decitre est un ensemble de librairies en Rhône-Alpes, présent avec des magasins physiques à Lyon, Grenoble, Chambéry, Annecy, et par son site de vente en ligne http://decitre.fr, un des sites majeurs de vente en ligne de livres en France. Une part de ses activités est aussi la maintenance d’une base de données de livres. Cette base est entre autres fournie à d’autres librairies au travers d’une application en SAAS nommée ORB (pour Outil de Recherche Bibliographique).
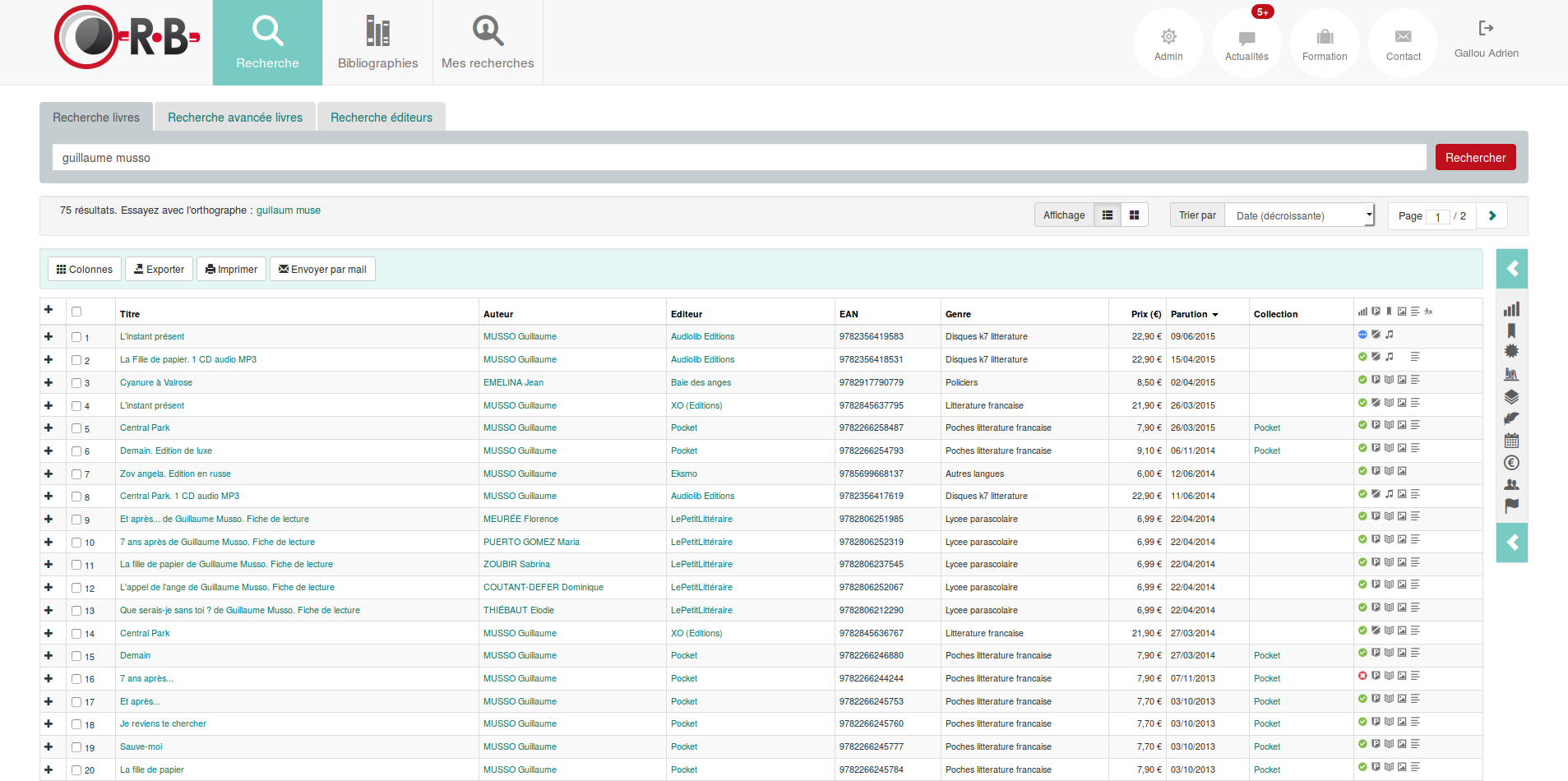
Sur cette application, l’utilisateur va pouvoir se connecter, faire différentes recherches (simples ou avancées) sur des livres ou éditeurs. Une fois les résultats affichés, il va pouvoir les affiner via des facettes. Chaque clic sur l’en-tête de colonne va permettre de modifier le tri. L’utilisateur peut ensuite exporter l’ensemble des résultats ou une sélection de produits dans un fichier PDF ou Excel, ainsi que consulter chacune des fiches produit listées.
Cette application a connu plusieurs refontes :
- une refonte applicative il y a deux ans,
- une refonte du moteur il y a un an.
Refonte applicative
L’application fonctionnait sous le CMS java Liferay, et était maintenue par une société externe. Nous avons arrêté d’utiliser ce CMS, ce qui nous a permis d’avoir, entre autres, une application plus ergonomique, et de logguer l’ensemble des recherches. En effet, jusqu’à présent nous n’avions aucun moyen de connaître les recherches effectuées dans l’application.
Nous avons donc créé une table qui contient :
- l’identifiant de la recherche
- l’utilisateur ayant effectué la recherche
- la date de la recherche
- le type de la recherche (livre ou éditeur, simple ou avancée)
- la recherche : un champ texte contenant du json représentant la recherche
- le nombre de résultats
- la durée de la recherche
Le fait de conserver les recherches effectuées par les utilisateurs nous était important, pour permettre de connaître le type de recherches effectuées, d’avoir des statistiques sur le nombre de résultats renvoyés, et de connaître dans quels cas les recherches ne renvoient pas de résultats. Le faire le plus tôt possible dans le projet nous a permis de collecter le plus de données possible, et ainsi d’effectuer des comparaisons entre les différents moteurs.
Refonte du moteur
L’application utilisait le moteur propriétaire de la société lyonnaise Antidot. Jusqu’alors l’application avait pour tri par défaut le tri par date de parution décroissant, que les utilisateurs trouvaient plus pertinent que le tri par pertinence.
Lors de la refonte vers Elasticsearch nous avons recherché à avoir une pertinence équivalente, et c’est après avoir utilisé Elasticsearch en production que nous avons commencé à travailler sur la pertinence.
La pertinence
La pertinence d’un moteur se décrit en deux points :
-
le nombre de résultats : il faut éviter d’avoir des recherches sans résultat tout en limitant le bruit (résultats non pertinents). Vu que le tri par pertinence n’est pas le seul tri disponible et que nous avons des fonctionnalités d’export des résultats, nous souhaitions limiter le bruit, ces résultats moins pertinents ne pouvaient pas se contenter de se trouver en fin de liste.
-
l’ordre des résultats : tri utile pour les utilisateurs : à la fois en fonction de la recherche/des documents, mais aussi de la disponibilité du produit, de sa date de sortie, de la langue, et d’autres critères.
Mise en place
L’amélioration de la pertinence s’est faite en 3 grandes étapes que nous allons décrire en détail ci-dessous :
- Travail préparatoire
- Hypothèses et validation lors du développement
- Indicateurs en production
Travail préparatoire
Explains faciles
Un explain sous Elasticsearch permet de savoir pourquoi un document a été remonté par la recherche ainsi que la façon dont son score a été calculé.
Cet explain est la première chose à étudier pour travailler sur la pertinence. En effet, connaître comment fonctionne le moteur permettra ensuite de savoir sur quoi jouer pour améliorer la pertinence.
Cet explain prend en paramètre dans le corps de la requête le paramètre query de la recherche. Il n’accepte pas en paramètre les éventuels paramètres passés à la requête search, comme les aggregations ou les suggestions. Il faut donc modifier le corps de la requête search pour le passer dans l’explain.
Les premières études sur les explains étaient assez fastidueuses. Nous devions récupérer la requête “search” dans la debug bar de notre application, modifier les paramètres pour ne conserver que le paramètre query. Et enfin effectuer la recherche dans elasticsearch-head en utilisant la bonne adresse.
Une des premières modifications effectuée lors du travail sur la pertinence fut l’ajout d’un lien pour permettre de faire facilement des explains.
Une colonne contenant un lien vers l’explain est maintenant affichée pour les administrateurs.
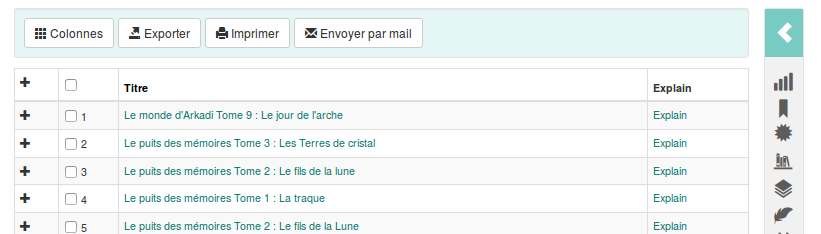
Au clic sur ce lien la page consultée nous affiche l’explain :

Autre avantage de cette solution : elle nous permet de faire les explains dans nos environnement de préproduction et production.
Sources lucène
Elasticsearch utilise Lucene pour l’indexation et la recherche (tout comme solr).
Afin de bien configurer les analyzers, il ne faut pas hésiter à rechercher le fonctionnement des différents filtres dans les sources de lucene. Voici par exemple la classe correspondant au fonctionnent du stemmer light_french, ou la liste des stopwords français. La documentation d’Elasticsearch ne décrit pas clairement leur mode de fonctionnement. Une meilleure compréhension de ceux-ci vous permettra de bien les choisir.
Connaitre les utilisateurs
Avant de commencer tout travail sur la pertinence, nous voulions avoir une vue d’ensemble sur le nombre de résultats renvoyés par les recherches.
Nous avons donc ajouté dans l’administration de notre application un graphique représentant le nombre de résultats de recherches, par tranches, et ce pour chaque semaine.
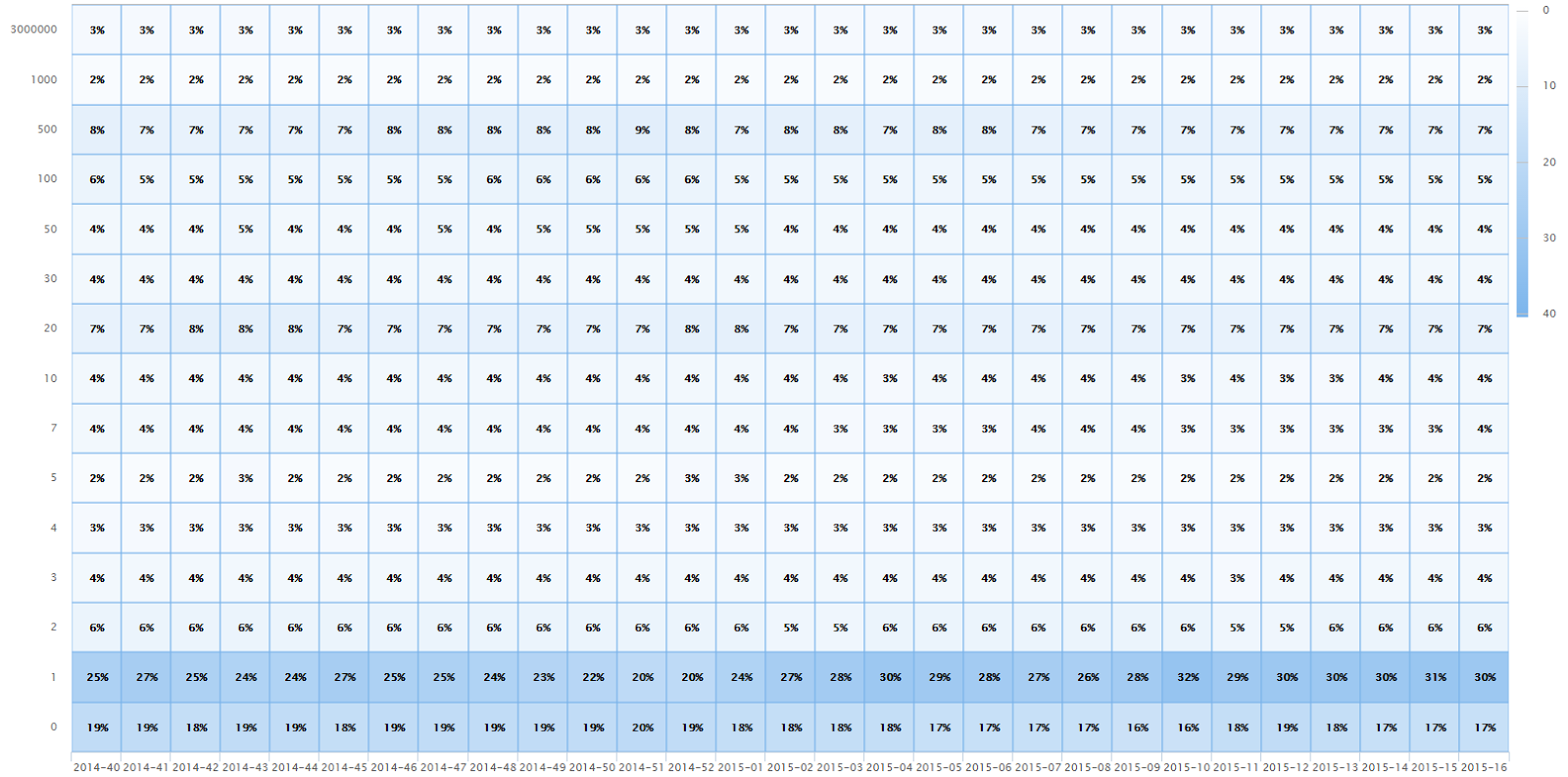
Nous avons, de plus, ajouté dans l’administration deux graphiques et tableaux nous permettant d’afficher la répartition des facettes utilisées ainsi que la répartition des champs de recherche avancée les plus utilisés.
####Passage des recherches dans Kibana
Dans un premier temps, pour étudier les recherches des utilisateurs, nous avions effectué une commande qui exportait dans un fichier une ligne par recherche simple, et ce pour une période donnée. Ce fichier était ensuite utilisé par les membres de l’équipe fonctionnelle pour étudier les recherches.
Cette façon de faire avait quelques limites :
- l’extraction nécessitait l’intervention d’un développeur
- il n’était pas pratique de rechercher / filtrer dans ce fichier
- cela ne permettait pas de faire des statistiques/tops sur ces recherches
- les statistiques étaient longues à obtenir et limitées à une période : pour faire ces statistiques nous devions décoder le json que nous avions stocké en base. Les statistiques étaient donc lentes, couteuses en mémoire et nous ne pouvions les lancer sur une très longue période (35 secondes pour obtenir des statistiques simples sur 5 mois de recherches).
Kibana est un outil de visualisation de requêtes effectuées sur Elasticsearch.
Nous donc avons crée une commande qui lit l’ensemble des recherches de notre table de log pour les insérer dans un index sur Elasticsearch; pour ensuite installer Kibana.
Kibana nous permet donc maintenant d’avoir, entre-autres, un top des recherches sans résultat. En interne, nous consultons ce top une fois par semaine, et prenons des mesures pour chaque cas. Ces cas sont sont variés : ajouter un livre manquant en base, ajouter de nouveaux synonymes, avoir de nouvelles pistes pour améliorer la configuration des analyzers…
Connaitre ses données
En plus de connaître le comportement des utilisateurs dans votre application, il est utile de bien connaître l’ensemble de données que vous requêtez.
Par exemple, lors du travail sur les boosts (pour augmenter le score de certains documents), nous nous demandions sur quel boost travailler en premier : sur la date de parution ou sur la disponibilité des produits (pour afficher augmenter le score des produits disponibles par rapport à celui des produits épuisés).
Nous nous sommes alors demandés s’il y avait une corrélation entre la date de parution et la disponibilité du produit.
Afin de savoir cela, cous avons donc généré un graphique des disponibilités en fonction de la date de parution.
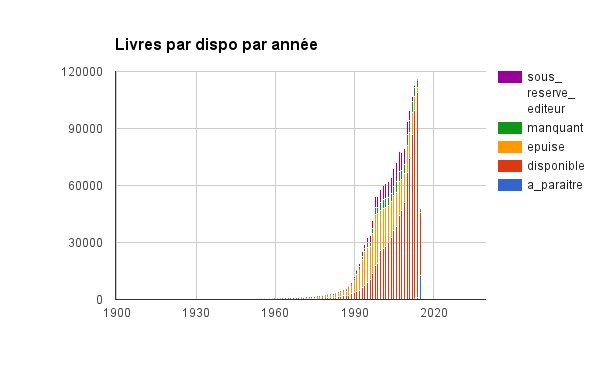
Ces chiffres ont permis de valider qu’il y avait bien une corrélation entre les date de parution et la disponibilté : les produits disponibles sont plus souvent parus récemment. Nous avons pu travailler tout d’abord sur la mise en place du boost sur la disponibilité. Le boost sur la date de parution est venu dans un second temps.
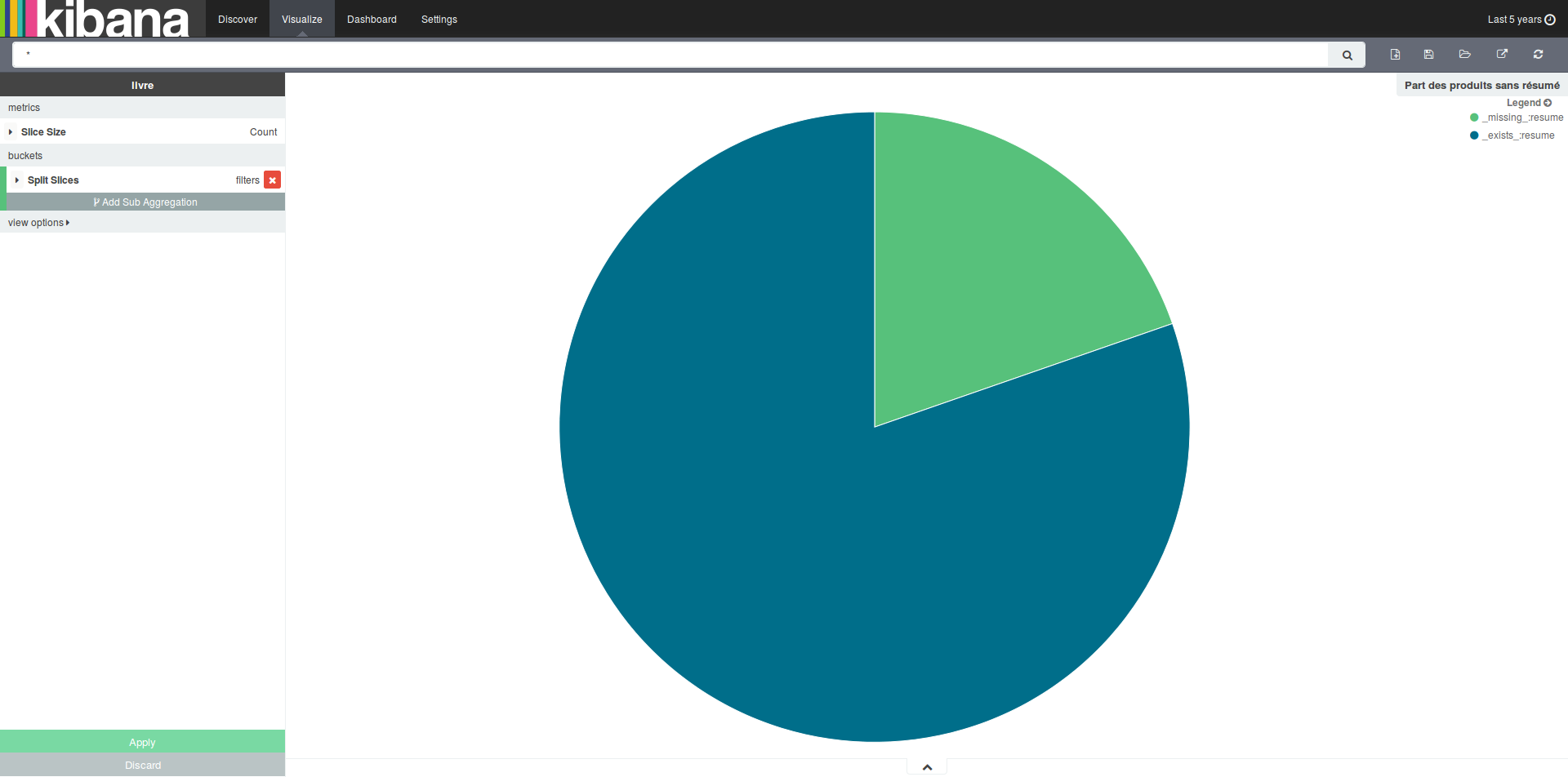
Nous avons effectué cela avant la mise en place de Kibana. Nous pouvons donc voir ici un autre avantage à celui-ci. En plus de pouvoir faire des requêtes sur notre index contenant l’historique des recherches, nous pouvons faire des recherches sur notre index contenant les livres. Ainsi lorsque nous nous sommes demandés quelle était la part des livres de notre base contenant un résumé, nous avons pu avoir la réponse dans Kibana.
Faire des hypothèses et les valider en amont
Nous avons donc maintenant des informations sur les recherches des utilisateurs ainsi que sur l’ensemble de données que l’on requête. Nous allons donc maintenant faire des hypothièses, par exemple :
- quel est l’impact de l’ajout de synonymes ?
- le nombre de zéro résultat va-t-il diminuer si l’on rajoute un filter dans notre analyzer ?
- les résultats sont-ils plus pertinents si l’on supprime certains champs sur lesquels portent la recherche ? Ces hypothèses seront à définir en fonction du résultat des études précédentes.
Travail sur le nombre de résultats
Afin de valider les différentes hypothèses modifiant le nombre de résultats, nous utilisons notre environnement de préproduction. Après avoir extrait la liste des recherches simples effectuées sur un mois (qui dans notre cas représente plusieurs centaines de milliers de recherches), nous les rejouons sur l’environnement de préproduction qui a été mis dans l’état de la production.
La commande rejouant ces recherches va nous générer un fichier CSV contenant la recherche et le nombre de résultats renvoyés. Après cela, nous effectuons un déploiement sur la préproduction pour la mettre dans l’état dans lequel nous voulons faire le test (par exemple, pour tester l’impact de la suppression du résumé des champs sur lesquels portent la recherche). Alors, nous relançons la commande pour rejouer toutes les requêtes extraites.
Nous nous retrouvons alors avec deux fichiers CSV, que nous allons fusionner pour donner un seul fichier contenant la recherche, le nombre de résultats avant et le nombre de résultats après.
Viens ensuite une étape fastidieuse, mais intéressante qui consiste à prendre un échantillon de recherches dont le nombre de résultats change, et à les étudier une à une.
Etude des recherches unes-à-unes
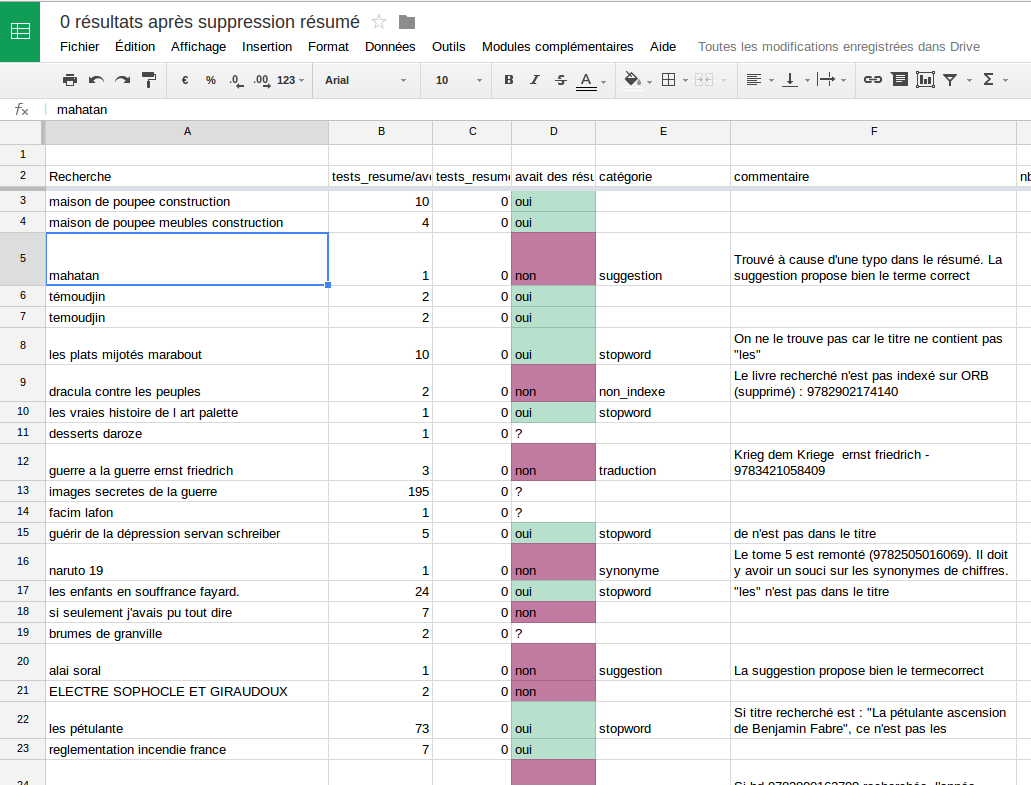
Ici l’étude va dépendre du cas testé, par exemple nous avons ici étudié les recherches qui passaient à 0 résultats. Nous exécutions chaque recherche en production et étudiions les résultats pour vérifier si ceux-ci étaient pertinents. Après en avoir étudié une centaine, nous pouvions donc valider si ces recherches passant à 0 résultats n’avaient pour la plupart pas de résultat pertinent.
Pour les recherches qui avaient des résultats pertinents avant modification mais n’en avaient plus après, nous indiquions pour chaque cas une piste pour permettre de retrouver ces résultats (ajout de synonymes, indexation de nouveaux champs conditionnellement, modification analyzer…).
Etude globale
Le travail précédent ne peut être effectué que sur un sous-ensemble des recherches. Afin d’avoir une vue d’ensemble des changements, nous utilisons graphiz. Une commande permet de partir du fichier contenant la recherche, le nombre de résultats avant et le nombre de résultats après, et va donner un fichier graphiz que l’on pourra convertir en image.
digraph {
node [shape=Mrecord]
0 [ceil=0, label="{0 résultat (55025 à 53268 : -3%)|{<f1> 1587|<f2> 119|<f3> 29|<f0> 53268}}", fillcolor=1, colorscheme=paired12, style=filled]
1 [ceil=5, label="{1 à 5 résultats (103563 à 103777 : +0%)|{<f2> 1272|<f3> 66|<f4> 20|<f1> 102190}}", fillcolor=2, colorscheme=paired12, style=filled]
2 [ceil=20, label="{6 à 20 résultats (23231 à 23546 : +1%)|{<f3> 914|<f4> 128|<f5> 33|<f2> 22155}}", fillcolor=3, colorscheme=paired12, style=filled]
3 [ceil=40, label="{21 à 40 résultats (8006 à 8238 : +3%)|{<f4> 689|<f5> 88|<f3> 7229}}", fillcolor=4, colorscheme=paired12, style=filled]
4 [ceil=80, label="{41 à 80 résultats (5789 à 6056 : +5%)|{<f5> 584|<f4> 5202}}", fillcolor=5, colorscheme=paired12, style=filled]
5 [ceil=1000, label="{81 à 1000 résultats (7615 à 8266 : +9%)|{<f6> 74|<f5> 7541}}", fillcolor=6, colorscheme=paired12, style=filled]
6 [ceil=30000000000, label="{sup 1000 résultats (1492 à 1570 : +5%)|{<f6> 1492}}", fillcolor=7, colorscheme=paired12, style=filled]
0 -> 0 [label="97%", color=1, colorscheme=paired12, penwidth=20]
0:f1 -> 1 [label="3%", color=1, colorscheme=paired12, penwidth=1, fontcolor=1]
0:f2 -> 2 [label="0%", color=1, colorscheme=paired12, penwidth=1, fontcolor=1]
0:f3 -> 3 [label="0%", color=1, colorscheme=paired12, penwidth=1, fontcolor=1]
1 -> 1 [label="99%", color=2, colorscheme=paired12, penwidth=20]
1:f2 -> 2 [label="1%", color=2, colorscheme=paired12, penwidth=1, fontcolor=2]
1:f3 -> 3 [label="0%", color=2, colorscheme=paired12, penwidth=1, fontcolor=2]
1:f4 -> 4 [label="0%", color=2, colorscheme=paired12, penwidth=1, fontcolor=2]
2 -> 2 [label="95%", color=3, colorscheme=paired12, penwidth=20]
2:f3 -> 3 [label="4%", color=3, colorscheme=paired12, penwidth=1, fontcolor=3]
2:f4 -> 4 [label="1%", color=3, colorscheme=paired12, penwidth=1, fontcolor=3]
2:f5 -> 5 [label="0%", color=3, colorscheme=paired12, penwidth=1, fontcolor=3]
3 -> 3 [label="90%", color=4, colorscheme=paired12, penwidth=19]
3:f4 -> 4 [label="9%", color=4, colorscheme=paired12, penwidth=2, fontcolor=4]
3:f5 -> 5 [label="1%", color=4, colorscheme=paired12, penwidth=1, fontcolor=4]
4 -> 4 [label="90%", color=5, colorscheme=paired12, penwidth=18]
4:f5 -> 5 [label="10%", color=5, colorscheme=paired12, penwidth=3, fontcolor=5]
5 -> 5 [label="99%", color=6, colorscheme=paired12, penwidth=20]
5:f6 -> 6 [label="1%", color=6, colorscheme=paired12, penwidth=1, fontcolor=6]
6 -> 6 [label="100%", color=7, colorscheme=paired12, penwidth=20]Cette image va représenter les mouvements des nombres de résultats dans chaque tranche. Nous pouvons par exemple voir que dans ce test, il y a eu 3% des recherches sans résultat en moins et que 1 587 recherches sont passées dans la tranche de 1 à 5 résultats.
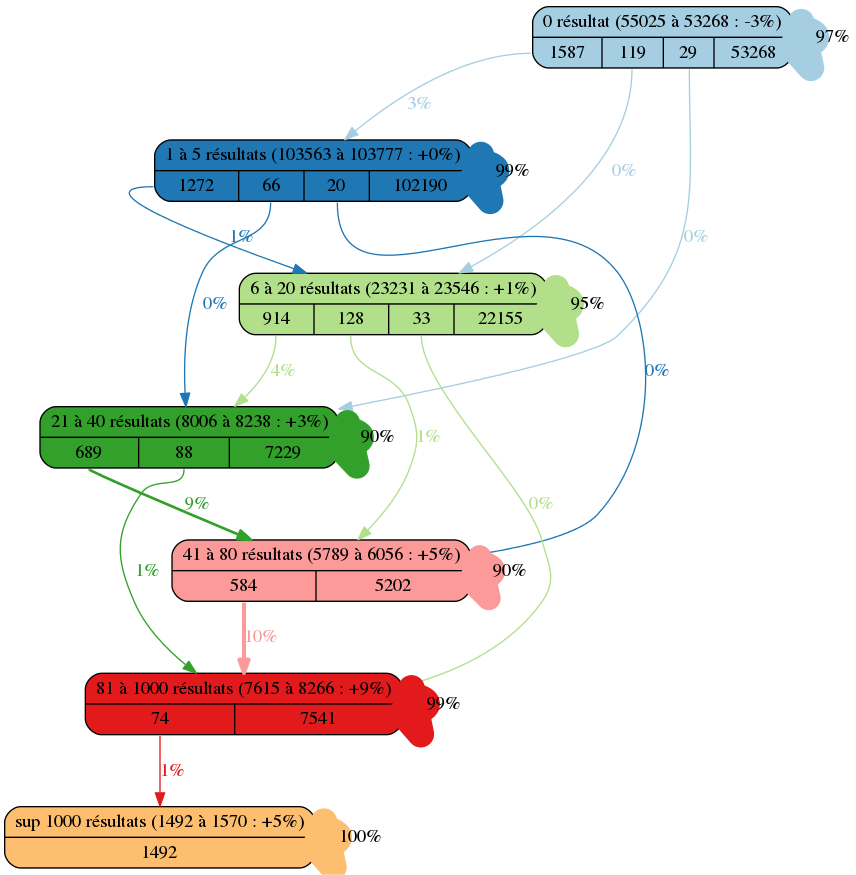
Cela permet donc de valider l’impact du changement sur le moteur.
Performance d’exécution des recherches
A savoir que la première version de la tâche rejouant toutes les recherches prenait 5 heures à s’exécuter. C’est assez peu pour rejouer toutes les recherches d’un mois mais un peu trop long pour avoir un retour rapide sur un changement du moteur. Nous avons donc joué sur deux choses :
- les aggrégations/suggestions : nous nous intéressons ici seulement aux nombres de résultats renvoyés, nous désactivons donc les aggrégations et les suggestions lorsque nous rejouons les recherches.
- parallélisation des requêtes : nous lançons maintenant une dizaine de recherches en parallèle au lieu de les lancer en série.
Après ces modifications, le lancement des rechecherches prend maintenant moins d’un quart d’heure, ce qui est beaucoup plus pratique pour avoir du feedback sur un changement.
Travail sur le tri
Afin de travailler sur les différents boosts, nous avons utilisé des tests fonctionnels.
Au départ leur utilisation n’était pas prévue pour le travail sur la pertinence, mais il se sont montrés très pratiques pour cette utilisation. Ces tests étaient écrits à la base pour valider qu’il n’y avait pas de régression sur moteur, et étaient executés tous les soirs sur l’environnement de préproduction.
Ces tests consistaient à utiliser l’outil de BDD Behat, pour décrire ce scénario :
- l’utilisateur se connecte à l’application
- il effectue une recherche simple “W”
- le livre d’identifiant “Z” se trouve entre les positions “X” et “Y” (nous ne cherchons pas le livre à une position fixe, principalement pour des raisons de maintenance du test, afin de ne pas devoir le modifier à chaque fois que le contenu de la base change et qu’un livre change de position).
Nous avions donc un tableau listant les différents scénarios à tester.
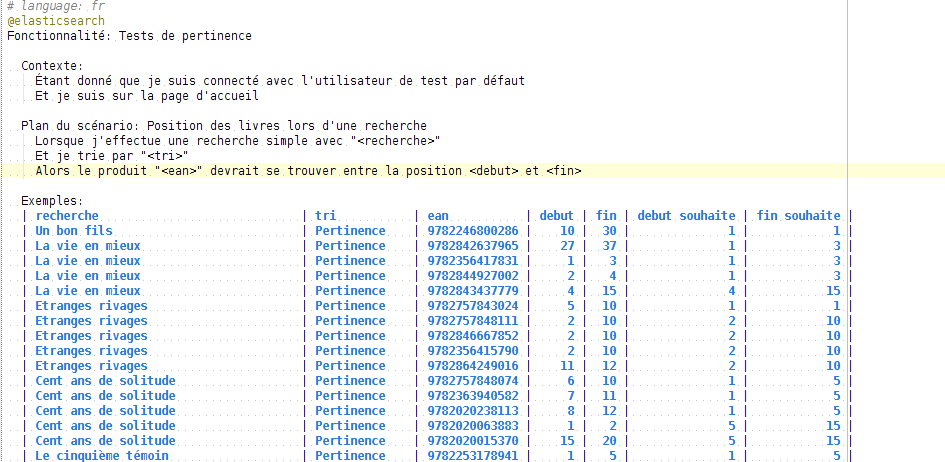
Lors du travail sur la pertinence, nous avons rajouté 2 nouvelles colonnes à ce tableau des scénarios : les positions X et Y dans le cas d’une pertinence idéale. Celles-ci étaient définies par le product owner du projet.
Il a fallu faire attention dans le choix des tests, pour que les tests soient représentatifs des recherches effectuées par les utilisateurs : une première version des tests ne contenait que des titres. Nous avons modifié cela pour avoir différents type de recherches (type/auteur, titre/auteur/tome, auteur/tome…), afin de mieux représenter les recherches des utilisateurs (Kibana a été utile pour les retrouver). Cela a permis d’éviter de sur-booster certains champs.
Indicateurs en production
Jusqu’à présent nous avons donc recueilli des informations sur les recherches des utilisateurs et sur le modèle de données requêté. Nous avons mis en place des outils pour travailler sur le nombre de résultats renvoyés, et sur l’amélioration du tri par pertinence.
Avant de mettre en production les changements nous avions besoin de mettre en place des indicateurs pour savoir si les changements avaient réellement un impact positif en production.
Pour cela, en plus de logguer l’ensemble des recherches effectuées, nous loggons toutes les consultations des fiches produit : lors du clic sur un lien vers une fiche produit, nous passons l’identifiant de la recherche ainsi que la position à laquelle se trouvait le produit dans les résultats de recherche.
Lorsqu’un utilisateur clique sur des positions “basses”, par exemple entre 1 et 5, cela veut dire que la pertinence est probablement bonne ; sinon si l’utilisateur clique plutôt sur des positions entre 30/40 ou plus, la pertinence n’est probablement pas assez bonne.
Nous avons donc modifié notre tâche créant l’index contenant l’historique des recherches, pour y ajouter les consultations des fiches produit de chaque recherche.
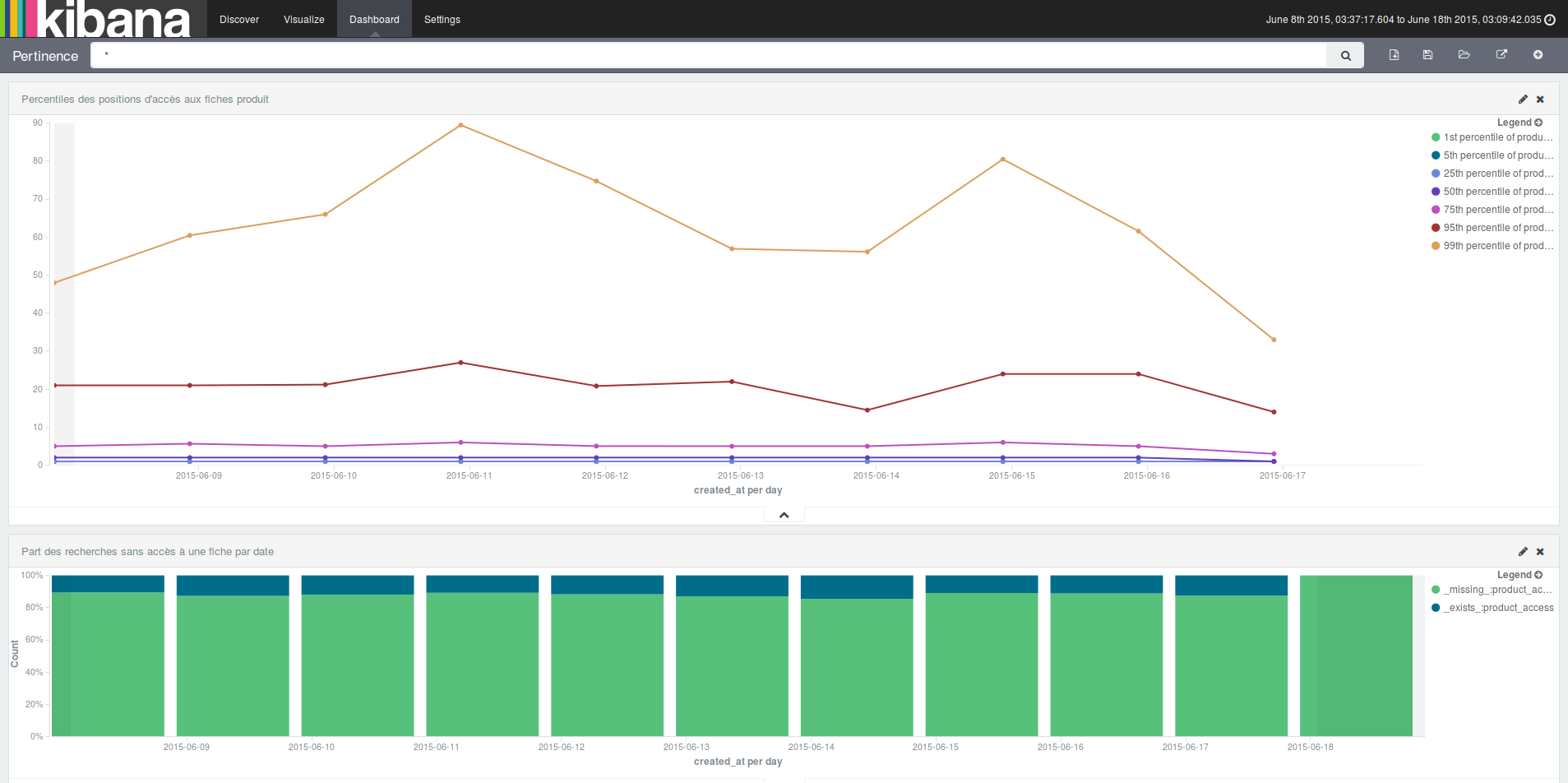
En plus de cela, nous pouvons maintenant savoir quelle est la part des recherches ayant donné lieu à la consultation d’une fiche produit. Par contre, comme tous les indicateurs, il faut bien faire attention à son interprétation. Ici l’utilisateur peut avoir eu toutes les informations nécessaires lors de la consultation du tableau des résultats.
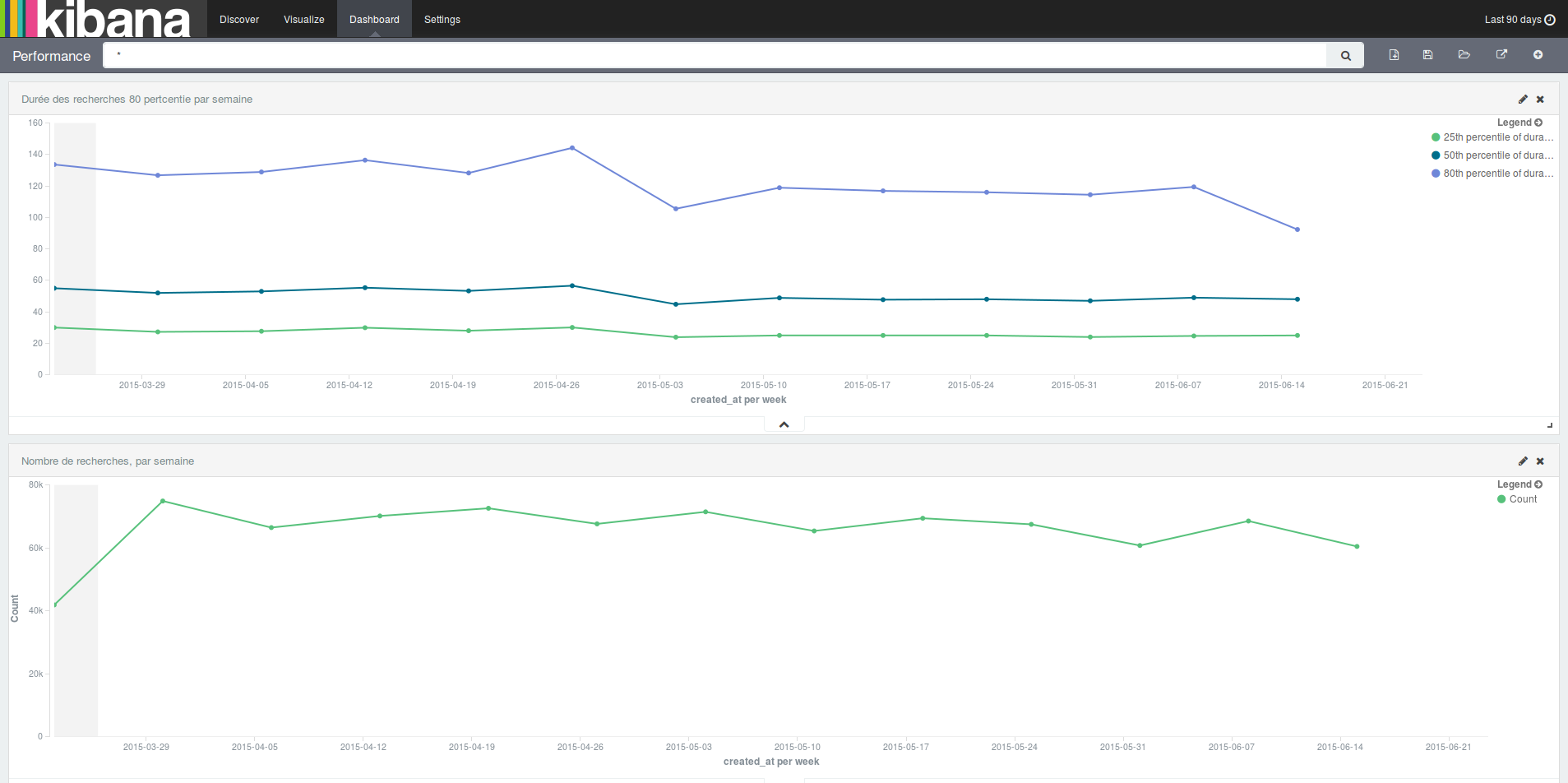
Un autre indicateur que l’on surveille lors des mises en production est le temps de réponse des requêtes. Nous validons que les temps de réponse d’Elasticsearch n’ont pas diminué ou ont très peu augmenté.
## Conclusion
Nous avons donc vu comment nous avons amélioré la pertinence :
- en collectant des informations (sur les utilisateurs, les recherches, les données)
- en faisant des hypothèses, des tests que nous validions et en itérant sur ces tests.
- en ayant des indicateurs en production pour suivre l’impact des modifications sur la pertinence et la performance.